-

We already discussed about Queue management solutions in the past, and I am always happy to write about it. Queue managers are not easy to implement, and there is a reson if IBM MQ Series is still a successful product. Some month ago, a big bank customer asked me to provide a small queue implementation to increase asynchronous internal processing of our payment solution.
The project had very strong contraints: I could not use existing queue system because they were not yet available, and I need to be able to provide microservice parallelism in a cloud-environent.
I have very little time to provide a solid solution, and re-inventing the wheel was not an option. Performance was important, but we plan to have a managable numbers of transactions per seconds, far behind modern cloud database capacity.
Challenge accepted.
Read More -
Random list of very interesting projects (will be updated, guys).
I will add my own ideas/impression as soon as possible.
From simpler to more complex stuff:
- sqlite-utils is a rather useful tool for managing SQLite databases, importing structured data and manipulating them from the command line
- A simple approach to use json, virtual column and indexes to get NoSQL features on SQLite
- Full text search FTS5
- Tools from datasette ecosystem (like DogSheep)
- Litestream Litestream is a standalone streaming replication tool for SQLite. It runs as a background process and safely replicates changes incrementally to another file or S3. Litestream only communicates with SQLite through the SQLite API so it will not corrupt your database.
- Dqlite (distributed SQLite) extends SQLite across a cluster of machines, with automatic failover and high-availability to keep your application running. It uses C-Raft, an optimised Raft implementation in C, to gain high-performance transactional consensus and fault tolerance while preserving SQlite’s outstanding efficiency and tiny footprint.
- Xlite: Query Excel and Open Document spreadsheets as SQLite virtual tables A lot of tools, from plugin like Xlite to command line export tools.
- STRICT TABLES SQLite uses duck-typing and it is very "elastic" on typing. Anyway in the more recent versions you can enable a "STRICT" typing, which does not work on date types, but can help to avoid mixing integer, real and strings in the same column.... see https://www.sqlite.org/stricttables.html
-
Abstract: Make a database which can be store historic modification is often considered a “secondary” activity, but bad design leads to databases that are difficult to optimize and often not very understandable. In this article we illustrate a simple method that respects the dictates of relational theory & is easy to understand. As a plus we will show it on SQLite, a small but powerful database system.
Read More -
Some co-workers started using Apache Kafka con a bunch of our Customers.
Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log[*].
To get this goal, Apache Kafka needs a complex servers setup, even more complex if you want the certification for the producing company (Confluent). Now, if you are planning to use Kafka like a simple JavaMessaeSystem (JMS) implementation, think twice before going on this route.PostgreSQL 12 offers a fair (and open source) partition implementation, whereas if money are not a problem, Oracle 12c can happy scale on billions of record before running into troubles (and ExaData can scale even more).
PostgreSQL and Oracle offer optimizations for partitioned data, called “Partition Pruning” in PostreSQL teminology:
With partition pruning enabled, the planner will examine the definition of each partition and prove that the partition need not be scanned because it could not contain any rows meeting the query's WHERE clause. When the planner can prove this, it excludes (prunes) the partition from the query plan.
This feature is quite brand new (popped in PostreSQL 11) but it is essential to a successful partition strategy. Before these feature, partitioning was a black magic art. Now it is simpler to manage.
Read More -
 I admit it. I suffered from an “algebra narcoleptic syndrome” during my relational database lessons at University (1996 circa). Lets talk about it
I admit it. I suffered from an “algebra narcoleptic syndrome” during my relational database lessons at University (1996 circa). Lets talk about it -
For a complete description see https://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
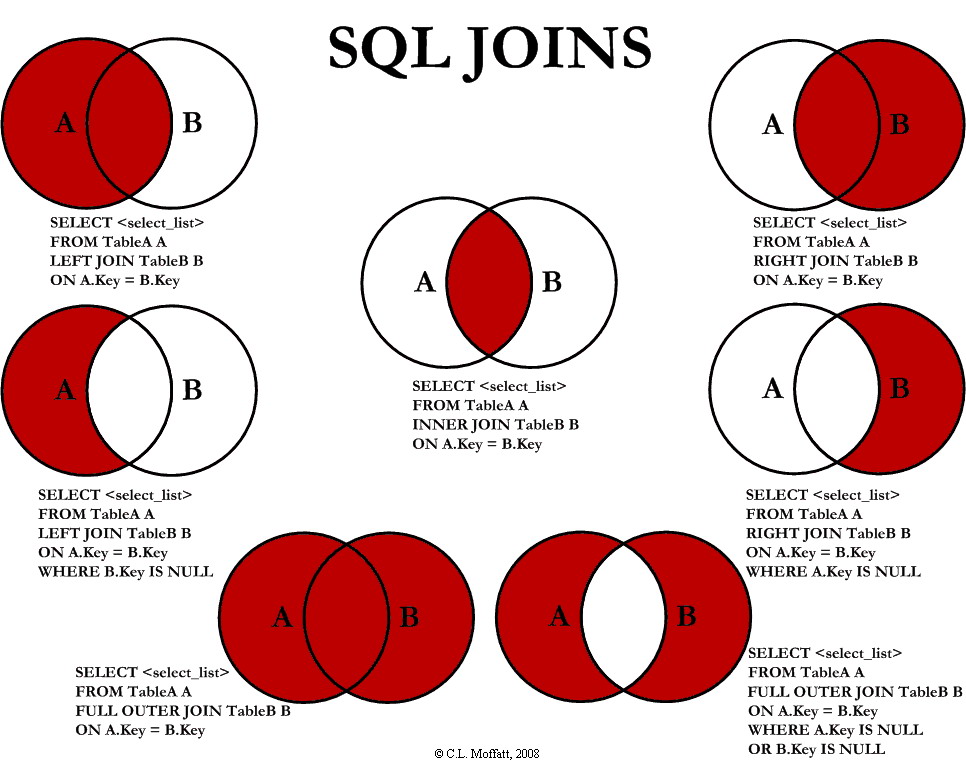
All the Join you want -

The Sqlite Oracle Compatibility Functions is an experimental compatibility layer for SQLite vs Oracle, written in Python 3.
It aims to provide a minimal compatibility with Oracle. The need was having some regular expression functions, and I do not like to work with risky C code, like this university project did
Read More -
Sometimes you need to remove nasty duplicate on a table, based on a subset of the column. On every big database there is something called “rowid” which can be used to indentify a column in a unique way. On PostgreSQL is called ctid, as we shall see:
Read More -
Oracle SQL Developer is full of nice feature, damned by a overwhelming options pane, like the one I will describe to you right now.
Even if Oracle databases (<12) does not support auto increment, you can easily ask to your sql data modeler to generate for you a sequence and a trigger in a automatic way.
Read More -
Oracle SQL Developer is full of nice feature, damned by a overwhelming options pane, like the one I will describe to you right now.
I will show here a very fast way of comparing different database and auto-generate migration script.
- Reverse engineer the source database using Oracle Data Modeler
- Now select the right arrow shown below:

- Select the destination datasource (more here) when asked.
- The compare pane will enable you to compare the databases.
But the default options will also use schema name to detect different object, so you will not get what you want in every scenario.
In 50% of my daily job, schema are different, so you must select the options below to fix it:
Select "Options" and then "Compare options". Then de-select "Use schema property" like suggested below:

- Push the "Sync new object". Then push the "DLL Preview" button and inspect the generated database.
- Bonus: by default the tool will not include tables to drop. Inspect the two pane ad check the table you want to drop in the left pane.
- Refrain launching the script without proper testing. You are migrating your valuable data.
-
I stumbled upon a very brain-f**k error on Oracle 10g on these days.
Context: the following query [sql]SELECT * FROM (
SELECT TO_NUMBER(CUSTOMER_ID) AS SNDG FROM BAD_CODES_TABLE WHERE
AND I_LIKE=UPPER(‘STATIC_CONDITION’) AND CUSTOMER_ID NOT LIKE ‘%P%’ ) S WHERE TO_NUMBER(S.SNDG) >2000[/sql] could trigger a Invalid number if CUSTOMER_ID column contains invalid numbers.Why?
Well…if you ask to “explain plan”, you will get something like
- a table full scan
- Filter Predicates AND
- I_LIKE=UPPER('STATIC_CONDITION')
- TO_NUMBER(S.SNDG) >2000
- CUSTOMER_ID NOT LIKE '%P%'
- Filter Predicates AND
Read More - a table full scan
-
Come evitare iniezione SQL: lato SQL Server (SP_EXECUTESQL)
In generale va evitato nel modo più assoluto la scrittura di query sql diamiche.Va evitato cioè l’uso lato SQL Server di sp_executesql e EXEC
Di seguito mostriamo come trasformare una query “dinamica” in una “statica”
Read More -

E’ facile fare un backup con sql server: Basta selezionare tasto destro Tasks>>Backup su un db. Ma come fare il restore?… Ecco un semplice script che chiarisce la cosa (non sempre lampante dallo wizard di restore….): [sql] – Usare il seguente comando per recuperare i parametri sorgente da usare nella MOVE – Nel nostro caso ssaranno MY_BACKUP e MY_BACKUP_log RESTORE FILELISTONLY FROM DISK = N’C:\TEMP\MY_BACKUP\Backup.bak’ ;
Read More

