-
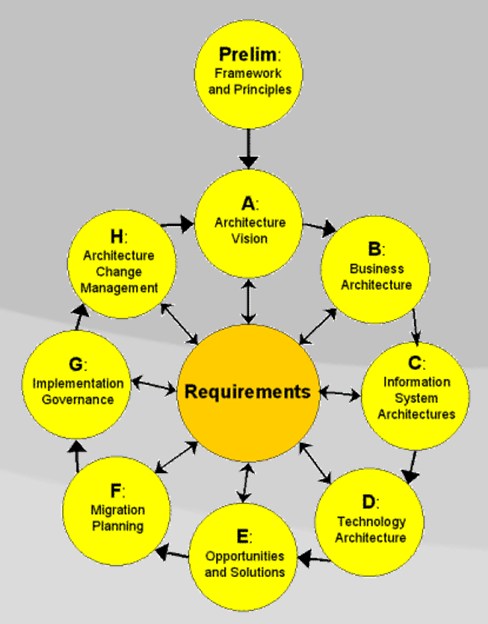 Ho avuto l’opportunità di certificarmi per The Open Group Architecture Framework (TOGAF per gli amici) e ho qualche spunto di riflessione, che riporto qui a futura memoria mia e vostra.
Ho avuto l’opportunità di certificarmi per The Open Group Architecture Framework (TOGAF per gli amici) e ho qualche spunto di riflessione, che riporto qui a futura memoria mia e vostra. -

L’anno scorso a giugno abbiamo affermato che 6,76% è il rendimento lordo, costante e minimo che il vostro investimento deve avere per raddoppiare il suo valore in 24 anni. Oggi aggiorniamo quanto ci siamo detti, in vista anche di quanto continua ad avvenire nello stretto di Hormuz.
Read More -
 A humble tool to find things, no ads no tracking and nothing more
A humble tool to find things, no ads no tracking and nothing more -
 Se il software diventasse ancora più a buon mercato, e la bolla AI sbriciolasse i servizi attuali? Cosa emergerebbe da questa fase succesiva?Proviamo a fare qualche riflessione.
Se il software diventasse ancora più a buon mercato, e la bolla AI sbriciolasse i servizi attuali? Cosa emergerebbe da questa fase succesiva?Proviamo a fare qualche riflessione. -
 Let’s pimp my homelab with a MacMini M1, tons of docker image and a little RasperryPI
Let’s pimp my homelab with a MacMini M1, tons of docker image and a little RasperryPI -
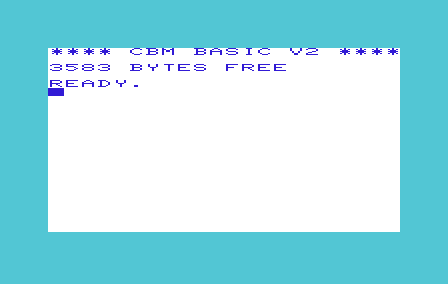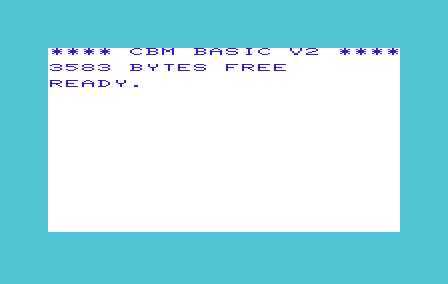
 Il Commodore Basic V2 è una piccola opera d’arte. Fu sviluppato da Bill Gates e venduto per una cifra una-tantum alla Commodore, che esaltata dalla cosa lo installò su più di un computer (dai primi PET fino al C/64). Pur disponendo di 71 comandi, stava in appena 9Kb di ROM. Stiamo parlando di meno di 5 pagine dattiloscritte. La pagina che state leggendo occupa almeno 5 volte tanto (!). Come è stato possibile? Scopriamolo assieme.
Il Commodore Basic V2 è una piccola opera d’arte. Fu sviluppato da Bill Gates e venduto per una cifra una-tantum alla Commodore, che esaltata dalla cosa lo installò su più di un computer (dai primi PET fino al C/64). Pur disponendo di 71 comandi, stava in appena 9Kb di ROM. Stiamo parlando di meno di 5 pagine dattiloscritte. La pagina che state leggendo occupa almeno 5 volte tanto (!). Come è stato possibile? Scopriamolo assieme. -
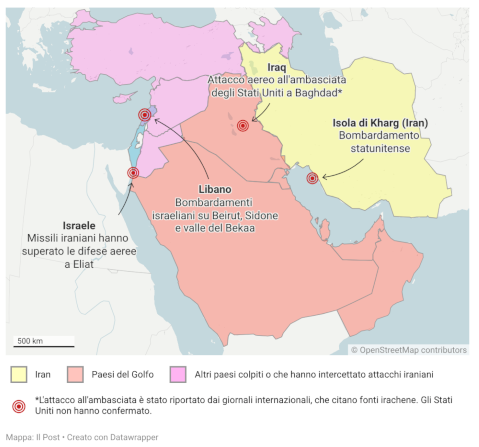 Iran-USA war is a very bad idea. It will provoke an economy shock on Europe (and Italy) and will increase our dependency from Russia and USA resources. A small note for the future, with facts and personal opinions
Iran-USA war is a very bad idea. It will provoke an economy shock on Europe (and Italy) and will increase our dependency from Russia and USA resources. A small note for the future, with facts and personal opinions -
 Creator of Quicksort and CSP died yesterday. A quick memo.
Creator of Quicksort and CSP died yesterday. A quick memo. -

NB: Questo articolo ho iniziato a scriverlo a fine Gennaio 2026, su ispirazione di questo, sulle “previsioni sbagliate” di famosi direttori internazionali. Verrà aggiornato di mese in mese.
Read More -
 Previsioni apocalittiche a parte, l’Intelligenza Artificiale è un game changer. Proviamo a fare una riflessione equilibrata e non scontata, partendo con una piccola novella. [Aggiornato]
Previsioni apocalittiche a parte, l’Intelligenza Artificiale è un game changer. Proviamo a fare una riflessione equilibrata e non scontata, partendo con una piccola novella. [Aggiornato] -

Per Natale mi hanno regalato il libro “Cesare” di Alberto Angela, un notevole sforzo editoriale di Mondadori per dare una rinfrescata ad un classico, il “De bello gallico”. Sono oltre metà e il mio demone mi ha chiesto di fare una recensione.
Read More -
In Italia pochissime persone investono i propri risparmi. Ci sono ragioni culturali e non, ma questo articolo vuole spingervi ad una riflessione più profonda su questo tema
-
A futura memoria, come ho sistemato un bug piuttosto subdolo tra MacOs e la mia tastiera GXTrust, che invertiva i due. tasti fondamentali per ogni sistemista Unix che si rispetti.
-
 Da anni, l’uso degli smartphone unito agli storage cloud (OneDrive, iCloud, ecc) ha portato molti di noi a lasciare memorizzate le foto sul cellulare. La baldanza con cui i cloud provider vogliono le nostre foto e i nostri documenti, disposti in qualche caso anche a darci lo spazio gratis, è oltremodo sospetta in questo periodo storico, dove la fame di dati per l’intelligenza artificiale è ovunque. Vediamo di riprendere il controllo delle nostre foto e delle nostre fatture
Da anni, l’uso degli smartphone unito agli storage cloud (OneDrive, iCloud, ecc) ha portato molti di noi a lasciare memorizzate le foto sul cellulare. La baldanza con cui i cloud provider vogliono le nostre foto e i nostri documenti, disposti in qualche caso anche a darci lo spazio gratis, è oltremodo sospetta in questo periodo storico, dove la fame di dati per l’intelligenza artificiale è ovunque. Vediamo di riprendere il controllo delle nostre foto e delle nostre fatture