Cassandra Compendium
Apache Cassandra Compendium, pasting together documentation from https://cassandra.apache.org/doc/latest/cassandra/data_modeling/index.html
Defining Application Queries
Let’s try the query-first approach to start designing the data model for a hotel application. The user interface design for the application is often a great artifact to use to begin identifying queries. Let’s assume that you’ve talked with the project stakeholders and your UX designers have produced user interface designs or wireframes for the key use cases. You’ll likely have a list of shopping queries like the following:
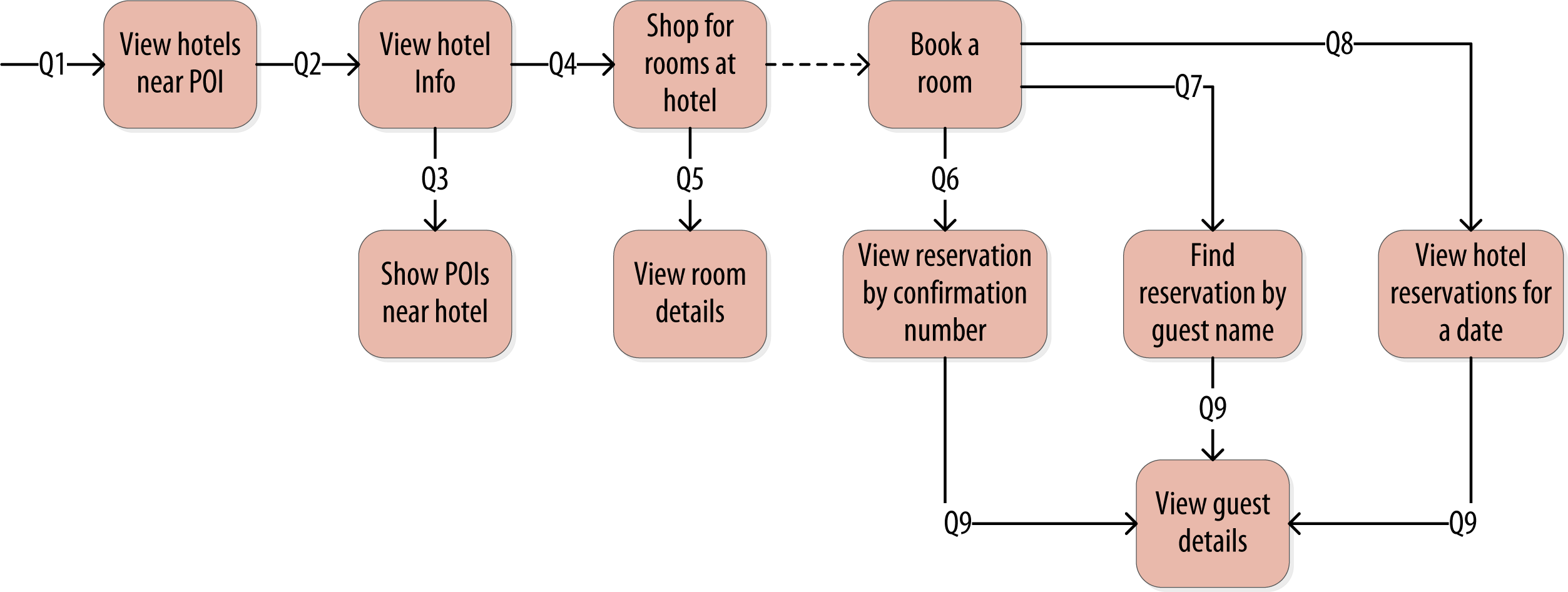
- Q1. Find hotels near a given point of interest.
- Q2. Find information about a given hotel, such as its name and location.
- Q3. Find points of interest near a given hotel.
- Q4. Find an available room in a given date range.
- Q5. Find the rate and amenities for a room.
It is often helpful to be able to refer to queries by a shorthand number rather that explaining them in full. The queries listed here are numbered Q1, Q2, and so on, which is how they are referenced in diagrams throughout the example.
Now if the application is to be a success, you’ll certainly want customers to be able to book reservations at hotels. This includes steps such as selecting an available room and entering their guest information. So clearly you will also need some queries that address the reservation and guest entities from the conceptual data model. Even here, however, you’ll want to think not only from the customer perspective in terms of how the data is written, but also in terms of how the data will be queried by downstream use cases.
You natural tendency as might be to focus first on designing the tables to store reservation and guest records, and only then start thinking about the queries that would access them. You may have felt a similar tension already when discussing the shopping queries before, thinking “but where did the hotel and point of interest data come from?” Don’t worry, you will see soon enough. Here are some queries that describe how users will access reservations:
- Q6. Lookup a reservation by confirmation number.
- Q7. Lookup a reservation by hotel, date, and guest name.
- Q8. Lookup all reservations by guest name.
- Q9. View guest details.
All of the queries are shown in the context of the workflow of the application in the figure below. Each box on the diagram represents a step in the application workflow, with arrows indicating the flows between steps and the associated query. If you’ve modeled the application well, each step of the workflow accomplishes a task that “unlocks” subsequent steps. For example, the “View hotels near POI” task helps the application learn about several hotels, including their unique keys. The key for a selected hotel may be used as part of Q2, in order to obtain detailed description of the hotel. The act of booking a room creates a reservation record that may be accessed by the guest and hotel staff at a later time through various additional queries.
Conceptual Data Modeling
First, let’s create a simple domain model that is easy to understand in the relational world, and then see how you might map it from a relational to a distributed hashtable model in Cassandra.
Let’s use an example that is complex enough to show the various data structures and design patterns, but not something that will bog you down with details. Also, a domain that’s familiar to everyone will allow you to concentrate on how to work with Cassandra, not on what the application domain is all about.
For example, let’s use a domain that is easily understood and that everyone can relate to: making hotel reservations.
The conceptual domain includes hotels, guests that stay in the hotels, a collection of rooms for each hotel, the rates and availability of those rooms, and a record of reservations booked for guests. Hotels typically also maintain a collection of “points of interest,” which are parks, museums, shopping galleries, monuments, or other places near the hotel that guests might want to visit during their stay. Both hotels and points of interest need to maintain geolocation data so that they can be found on maps for mashups, and to calculate distances.
The conceptual domain is depicted below using the entity–relationship model popularized by Peter Chen. This simple diagram represents the entities in the domain with rectangles, and attributes of those entities with ovals. Attributes that represent unique identifiers for items are underlined. Relationships between entities are represented as diamonds, and the connectors between the relationship and each entity show the multiplicity of the connection.
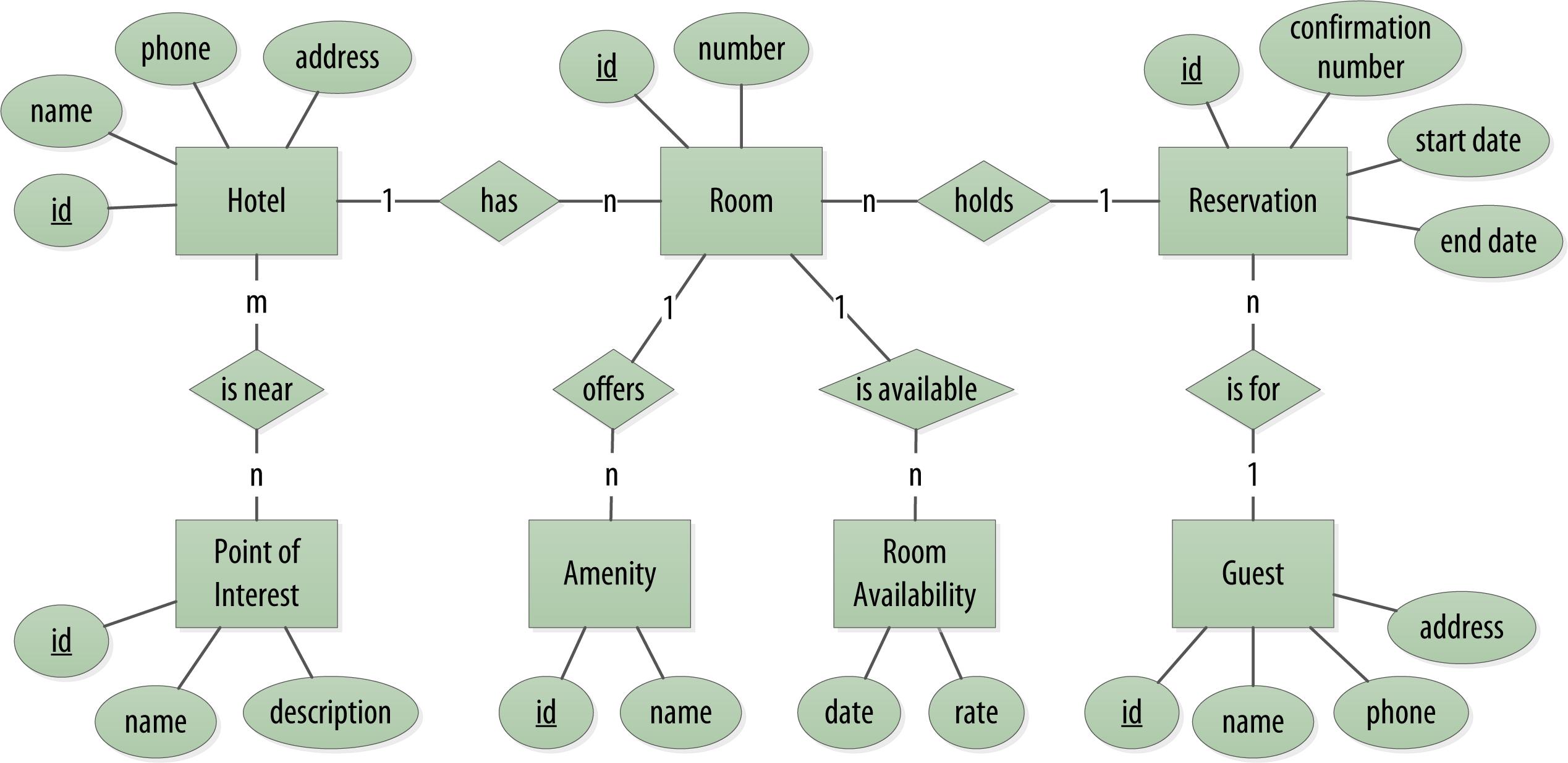
Obviously, in the real world, there would be many more considerations and much more complexity. For example, hotel rates are notoriously dynamic, and calculating them involves a wide array of factors. Here you’re defining something complex enough to be interesting and touch on the important points, but simple enough to maintain the focus on learning Cassandra.
Logical Data Modeling
Now that you have defined your queries, you’re ready to begin designing Cassandra tables. First, create a logical model containing a table for each query, capturing entities and relationships from the conceptual model.
To name each table, you’ll identify the primary entity type for which you are querying and use that to start the entity name. If you are querying by attributes of other related entities, append those to the table name, separated with by. For example, hotels_by_poi.
Next, you identify the primary key for the table, adding partition key columns based on the required query attributes, and clustering columns in order to guarantee uniqueness and support desired sort ordering.
The design of the primary key is extremely important, as it will determine how much data will be stored in each partition and how that data is organized on disk, which in turn will affect how quickly Cassandra processes reads.
Complete each table by adding any additional attributes identified by the query. If any of these additional attributes are the same for every instance of the partition key, mark the column as static.
Now that was a pretty quick description of a fairly involved process, so it will be worthwhile to work through a detailed example. First, let’s introduce a notation that you can use to represent logical models.
Several individuals within the Cassandra community have proposed notations for capturing data models in diagrammatic form. This document uses a notation popularized by Artem Chebotko which provides a simple, informative way to visualize the relationships between queries and tables in your designs. This figure shows the Chebotko notation for a logical data model.
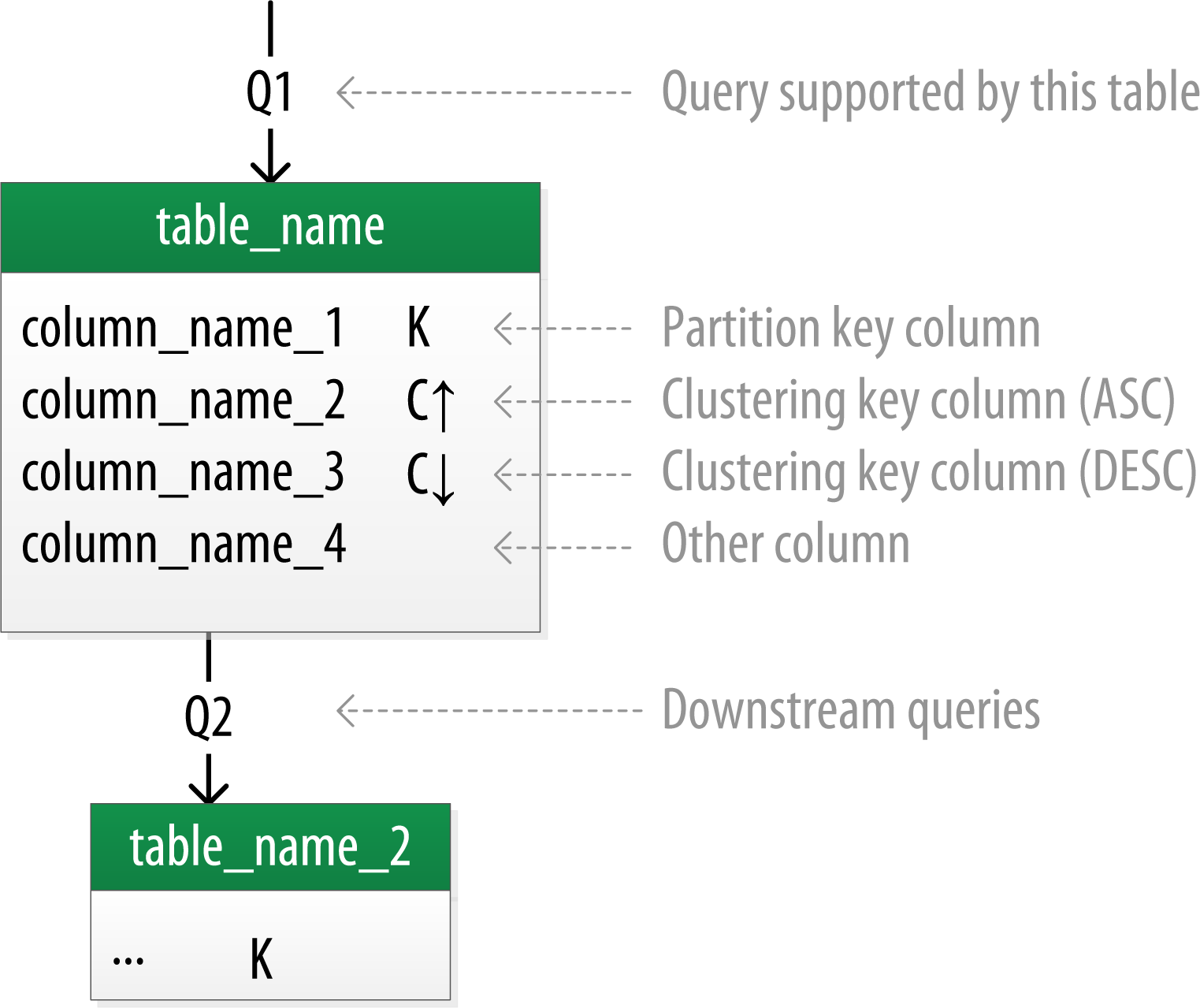
Each table is shown with its title and a list of columns. Primary key columns are identified via symbols such as K for partition key columns and C↑ or C↓ to represent clustering columns. Lines are shown entering tables or between tables to indicate the queries that each table is designed to support.
Hotel Logical Data Model
The figure below shows a Chebotko logical data model for the queries involving hotels, points of interest, rooms, and amenities. One thing you’ll notice immediately is that the Cassandra design doesn’t include dedicated tables for rooms or amenities, as you had in the relational design. This is because the workflow didn’t identify any queries requiring this direct access.
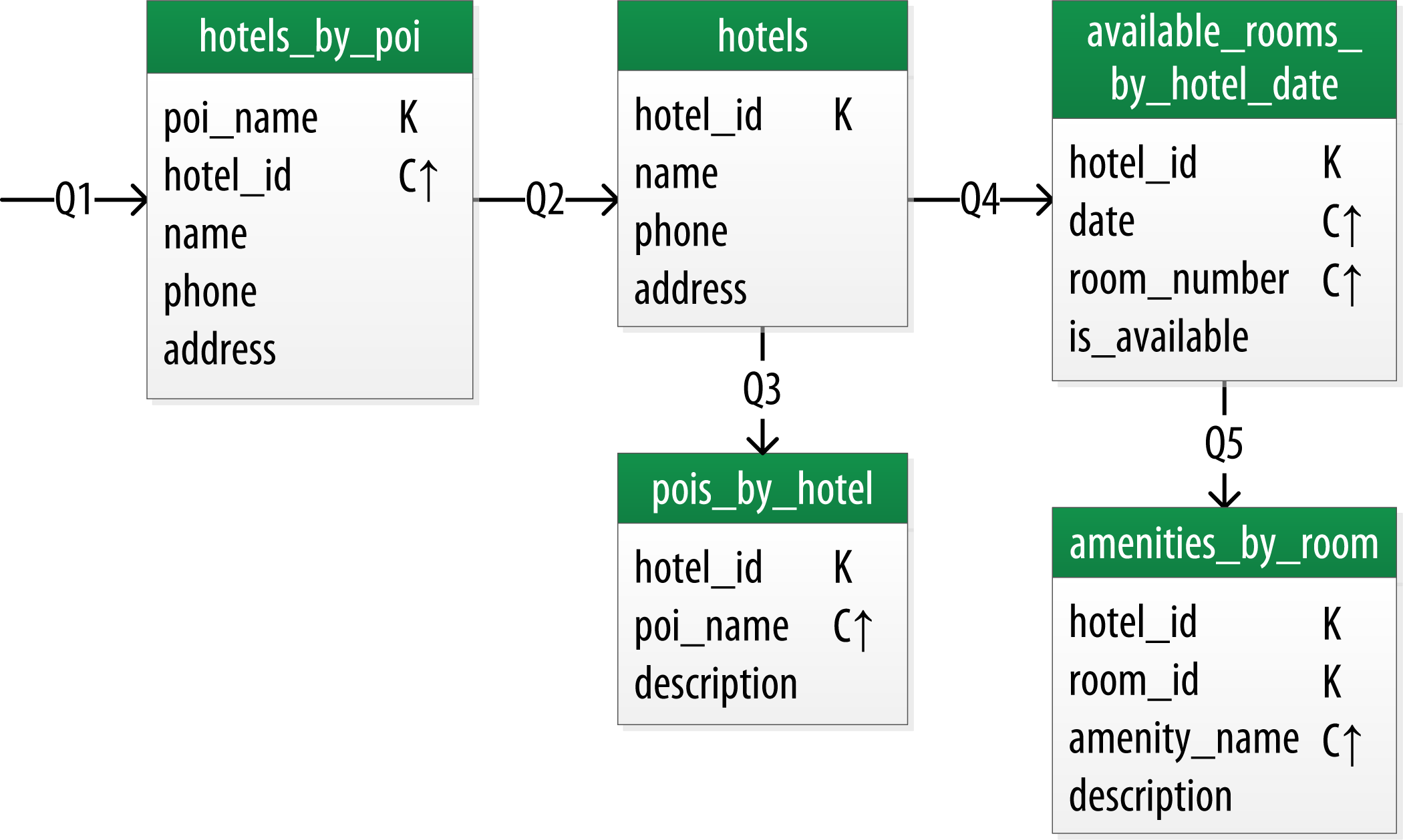
Let’s explore the details of each of these tables.
The first query Q1 is to find hotels near a point of interest, so you’ll call this table hotels_by_poi. Searching by a named point of interest is a clue that the point of interest should be a part of the primary key. Let’s reference the point of interest by name, because according to the workflow that is how users will start their search.
You’ll note that you certainly could have more than one hotel near a given point of interest, so you’ll need another component in the primary key in order to make sure you have a unique partition for each hotel. So you add the hotel key as a clustering column.
An important consideration in designing your table’s primary key is making sure that it defines a unique data element. Otherwise you run the risk of accidentally overwriting data.
Now for the second query (Q2), you’ll need a table to get information about a specific hotel. One approach would have been to put all of the attributes of a hotel in the hotels_by_poi table, but you added only those attributes that were required by the application workflow.
From the workflow diagram, you know that the hotels_by_poi table is used to display a list of hotels with basic information on each hotel, and the application knows the unique identifiers of the hotels returned. When the user selects a hotel to view details, you can then use Q2, which is used to obtain details about the hotel. Because you already have the hotel_id from Q1, you use that as a reference to the hotel you’re looking for. Therefore the second table is just called hotels.
Another option would have been to store a set of poi_names in the hotels table. This is an equally valid approach. You’ll learn through experience which approach is best for your application.
Q3 is just a reverse of Q1—looking for points of interest near a hotel, rather than hotels near a point of interest. This time, however, you need to access the details of each point of interest, as represented by the pois_by_hotel table. As previously, you add the point of interest name as a clustering key to guarantee uniqueness.
At this point, let’s now consider how to support query Q4 to help the user find available rooms at a selected hotel for the nights they are interested in staying. Note that this query involves both a start date and an end date. Because you’re querying over a range instead of a single date, you know that you’ll need to use the date as a clustering key. Use the hotel_id as a primary key to group room data for each hotel on a single partition, which should help searches be super fast. Let’s call this the available_rooms_by_hotel_date table.
To support searching over a range, use clustering columns <clustering-columns> to store attributes that you need to access in a range query. Remember that the order of the clustering columns is important.
The design of the available_rooms_by_hotel_date table is an instance of the wide partition pattern. This pattern is sometimes called the wide row pattern when discussing databases that support similar models, but wide partition is a more accurate description from a Cassandra perspective. The essence of the pattern is to group multiple related rows in a partition in order to support fast access to multiple rows within the partition in a single query.
In order to round out the shopping portion of the data model, add the amenities_by_room table to support Q5. This will allow users to view the amenities of one of the rooms that is available for the desired stay dates.
Reservation Logical Data Model
Now let’s switch gears to look at the reservation queries. The figure shows a logical data model for reservations. You’ll notice that these tables represent a denormalized design; the same data appears in multiple tables, with differing keys.
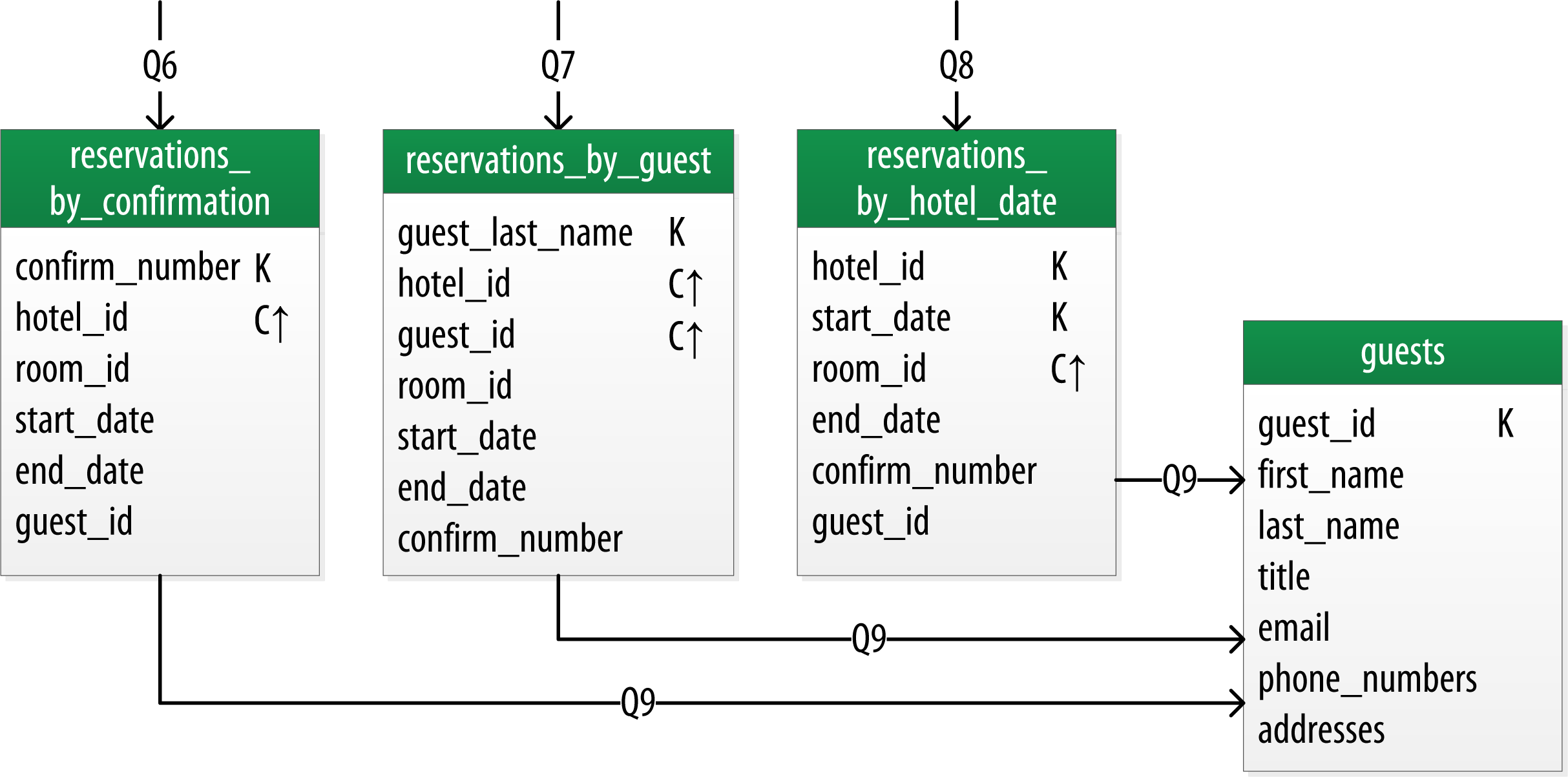
In order to satisfy Q6, the reservations_by_guest table can be used to look up the reservation by guest name. You could envision query Q7 being used on behalf of a guest on a self-serve website or a call center agent trying to assist the guest. Because the guest name might not be unique, you include the guest ID here as a clustering column as well.
Q8 and Q9 in particular help to remind you to create queries that support various stakeholders of the application, not just customers but staff as well, and perhaps even the analytics team, suppliers, and so on.
The hotel staff might wish to see a record of upcoming reservations by date in order to get insight into how the hotel is performing, such as what dates the hotel is sold out or undersold. Q8 supports the retrieval of reservations for a given hotel by date.
Finally, you create a guests table. This provides a single location that used to store guest information. In this case, you specify a separate unique identifier for guest records, as it is not uncommon for guests to have the same name. In many organizations, a customer database such as the guests table would be part of a separate customer management application, which is why other guest access patterns were omitted from the example.
Patterns and Anti-Patterns
As with other types of software design, there are some well-known patterns and anti-patterns for data modeling in Cassandra. You’ve already used one of the most common patterns in this hotel model—the wide partition pattern.
The time series pattern is an extension of the wide partition pattern. In this pattern, a series of measurements at specific time intervals are stored in a wide partition, where the measurement time is used as part of the partition key. This pattern is frequently used in domains including business analysis, sensor data management, and scientific experiments.
The time series pattern is also useful for data other than measurements. Consider the example of a banking application. You could store each customer’s balance in a row, but that might lead to a lot of read and write contention as various customers check their balance or make transactions. You’d probably be tempted to wrap a transaction around writes just to protect the balance from being updated in error. In contrast, a time series–style design would store each transaction as a timestamped row and leave the work of calculating the current balance to the application.
One design trap that many new users fall into is attempting to use Cassandra as a queue. Each item in the queue is stored with a timestamp in a wide partition. Items are appended to the end of the queue and read from the front, being deleted after they are read. This is a design that seems attractive, especially given its apparent similarity to the time series pattern. The problem with this approach is that the deleted items are now tombstones <asynch-deletes> that Cassandra must scan past in order to read from the front of the queue. Over time, a growing number of tombstones begins to degrade read performance.
The queue anti-pattern serves as a reminder that any design that relies on the deletion of data is potentially a poorly performing design.
Physical Data Modeling
Once you have a logical data model defined, creating the physical model is a relatively simple process.
You walk through each of the logical model tables, assigning types to each item. You can use any valid CQL data type <data-types>, including the basic types, collections, and user-defined types. You may identify additional user-defined types that can be created to simplify your design.
After you’ve assigned data types, you analyze the model by performing size calculations and testing out how the model works. You may make some adjustments based on your findings. Once again let’s cover the data modeling process in more detail by working through an example.
Before getting started, let’s look at a few additions to the Chebotko notation for physical data models. To draw physical models, you need to be able to add the typing information for each column. This figure shows the addition of a type for each column in a sample table.

The figure includes a designation of the keyspace containing each table and visual cues for columns represented using collections and user-defined types. Note the designation of static columns and secondary index columns. There is no restriction on assigning these as part of a logical model, but they are typically more of a physical data modeling concern.
Hotel Physical Data Model
Now let’s get to work on the physical model. First, you need keyspaces to contain the tables. To keep the design relatively simple, create a hotel keyspace to contain tables for hotel and availability data, and a reservation keyspace to contain tables for reservation and guest data. In a real system, you might divide the tables across even more keyspaces in order to separate concerns.
For the hotels table, use Cassandra’s text type to represent the hotel’s id. For the address, create an address user defined type. Use the text type to represent the phone number, as there is considerable variance in the formatting of numbers between countries.
While it would make sense to use the uuid type for attributes such as the hotel_id, this document uses mostly text attributes as identifiers, to keep the samples simple and readable. For example, a common convention in the hospitality industry is to reference properties by short codes like “AZ123” or “NY229”. This example uses these values for hotel_ids, while acknowledging they are not necessarily globally unique.
You’ll find that it’s often helpful to use unique IDs to uniquely reference elements, and to use these uuids as references in tables representing other entities. This helps to minimize coupling between different entity types. This may prove especially effective if you are using a microservice architectural style for your application, in which there are separate services responsible for each entity type.
As you work to create physical representations of various tables in the logical hotel data model, you use the same approach. The resulting design is shown in this figure:
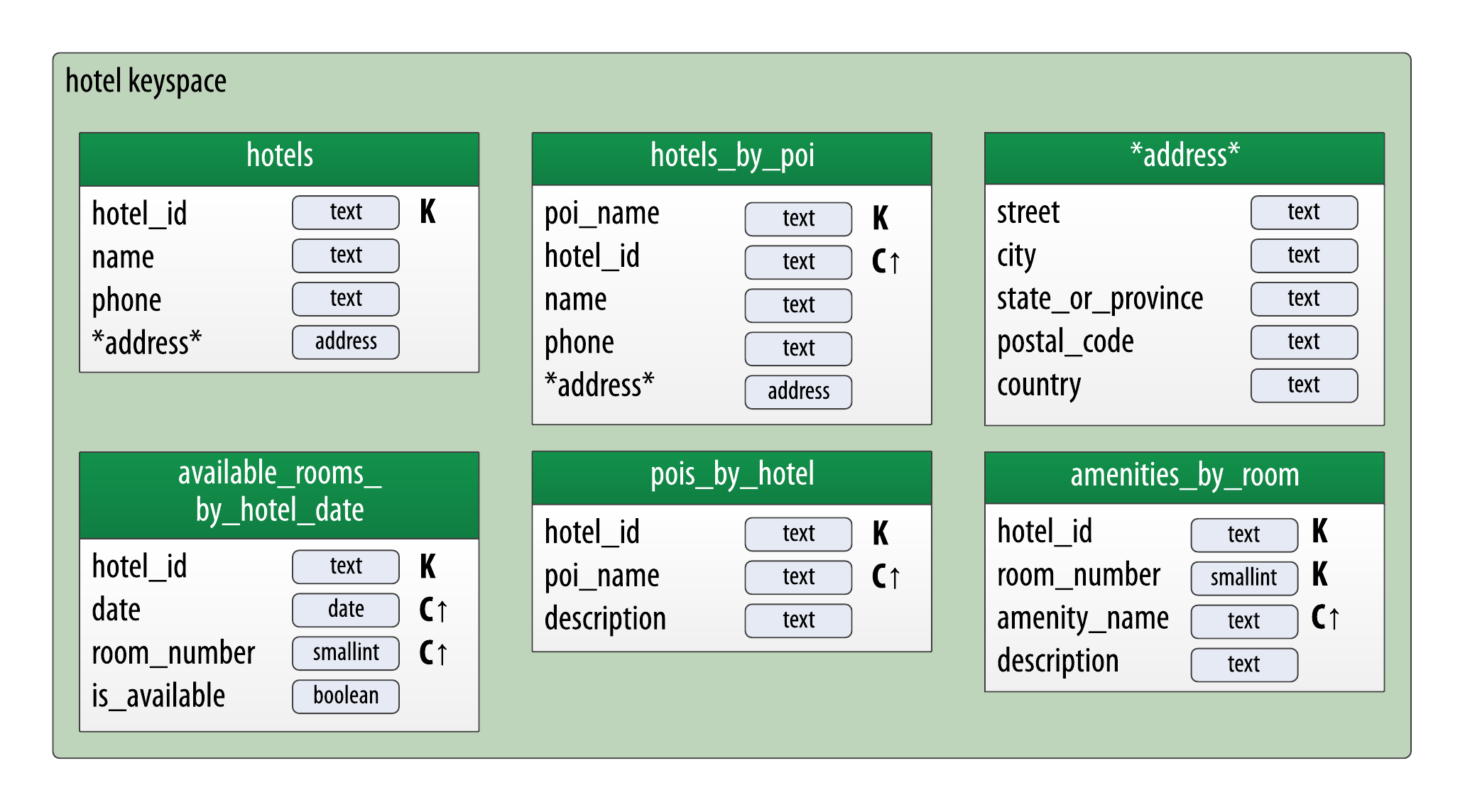
Note that the address type is also included in the design. It is designated with an asterisk to denote that it is a user-defined type, and has no primary key columns identified. This type is used in the hotels and hotels_by_poi tables.
User-defined types are frequently used to help reduce duplication of non-primary key columns, as was done with the address user-defined type. This can reduce complexity in the design.
Remember that the scope of a UDT is the keyspace in which it is defined. To use address in the reservation keyspace defined below design, you’ll have to declare it again. This is just one of the many trade-offs you have to make in data model design.
Reservation Physical Data Model
Now, let’s examine reservation tables in the design. Remember that the logical model contained three denormalized tables to support queries for reservations by confirmation number, guest, and hotel and date. For the first iteration of your physical data model design, assume you’re going to manage this denormalization manually. Note that this design could be revised to use Cassandra’s (experimental) materialized view feature.

Note that the address type is reproduced in this keyspace and guest_id is modeled as a uuid type in all of the tables.
Defining Database Schema
Once you have finished evaluating and refining the physical model, you’re ready to implement the schema in CQL. Here is the schema for the hotel keyspace, using CQL’s comment feature to document the query pattern supported by each table:
CREATE KEYSPACE hotel WITH replication =
{‘class’: ‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE hotel.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE hotel.hotels_by_poi (
poi_name text,
hotel_id text,
name text,
phone text,
address frozen<address>,
PRIMARY KEY ((poi_name), hotel_id) )
WITH comment = ‘Q1. Find hotels near given poi’
AND CLUSTERING ORDER BY (hotel_id ASC) ;
CREATE TABLE hotel.hotels (
id text PRIMARY KEY,
name text,
phone text,
address frozen<address>,
pois set )
WITH comment = ‘Q2. Find information about a hotel’;
CREATE TABLE hotel.pois_by_hotel (
poi_name text,
hotel_id text,
description text,
PRIMARY KEY ((hotel_id), poi_name) )
WITH comment = Q3. Find pois near a hotel’;
CREATE TABLE hotel.available_rooms_by_hotel_date (
hotel_id text,
date date,
room_number smallint,
is_available boolean,
PRIMARY KEY ((hotel_id), date, room_number) )
WITH comment = ‘Q4. Find available rooms by hotel date’;
CREATE TABLE hotel.amenities_by_room (
hotel_id text,
room_number smallint,
amenity_name text,
description text,
PRIMARY KEY ((hotel_id, room_number), amenity_name) )
WITH comment = ‘Q5. Find amenities for a room’;
Notice that the elements of the partition key are surrounded with parentheses, even though the partition key consists of the single column poi_name. This is a best practice that makes the selection of partition key more explicit to others reading your CQL.
Similarly, here is the schema for the reservation keyspace:
CREATE KEYSPACE reservation WITH replication = {‘class’:
‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE reservation.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE reservation.reservations_by_confirmation (
confirm_number text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
guest_id uuid,
PRIMARY KEY (confirm_number) )
WITH comment = ‘Q6. Find reservations by confirmation number’;
CREATE TABLE reservation.reservations_by_hotel_date (
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((hotel_id, start_date), room_number) )
WITH comment = ‘Q7. Find reservations by hotel and date’;
CREATE TABLE reservation.reservations_by_guest (
guest_last_name text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((guest_last_name), hotel_id) )
WITH comment = ‘Q8. Find reservations by guest name’;
CREATE TABLE reservation.guests (
guest_id uuid PRIMARY KEY,
first_name text,
last_name text,
title text,
emails set,
phone_numbers list,
addresses map<text,
frozen<address>,
confirm_number text )
WITH comment = ‘Q9. Find guest by ID’;
You now have a complete Cassandra schema for storing data for a hotel application.
Material adapted from Cassandra, The Definitive Guide. Published by O’Reilly Media, Inc. Copyright © 2020 Jeff Carpenter, Eben Hewitt. All rights reserved. Used with permission.